
What is Mamba
Mamba 是一种基于结构化状态空间序列模型(SSMs)的新兴架构,旨在高效捕捉序列数据中的复杂依赖性,成为 Transformer 的强大竞争对手。受经典状态空间模型启发,Mamba 融合了循环神经网络(RNN)和卷积神经网络(CNN)的特点,通过递归或卷积操作实现计算成本与序列长度的线性或近线性扩展,显著降低计算复杂度。
具体而言,Mamba 的核心优势包括:
- 选择机制:引入简单而有效的选择机制,通过输入参数化 SSM 参数,过滤无关信息,保留必要数据。
- 硬件感知算法:采用递归扫描而非卷积计算,优化硬件性能,在 A100 GPU 上实现高达 3 倍的加速。
- 建模能力:在保持与 Transformer 相当的建模能力的同时,具备近线性的可扩展性,适用于复杂和长序列数据。
这些特性使 Mamba 成为处理多领域任务的理想基础模型,已在计算机视觉、自然语言处理和医疗保健等领域展现出卓越性能。例如,Vim 模型在高分辨率图像特征提取中比 DeiT 快 2.8 倍,节省 86.8% 的 GPU 内存;而在语言建模任务中,改进的选择性 SSM 架构实现了 2-8 倍的加速。Mamba 的高效性和灵活性使其有望在多个研究和应用领域引发革命性变革。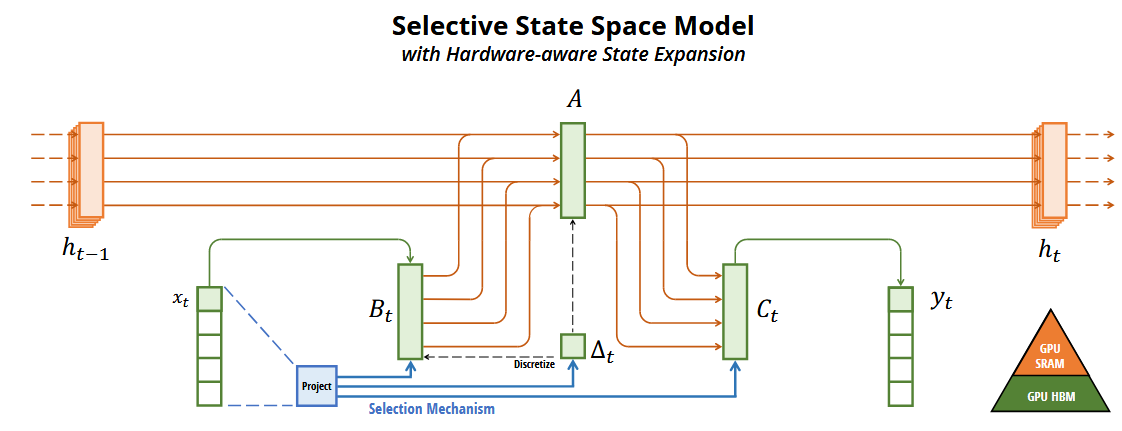
Mamba 架构的主要创新点包括:对输入信息有选择性处理、硬件感知的算法、更简单的架构。它是第一个真正实现匹配 Transformer 性能的线性时间序列模型,建立在更现代的适用于深度学习的结构化 SSM(S4, Structured SSM)基础上,与经典架构 RNN 有相似之处。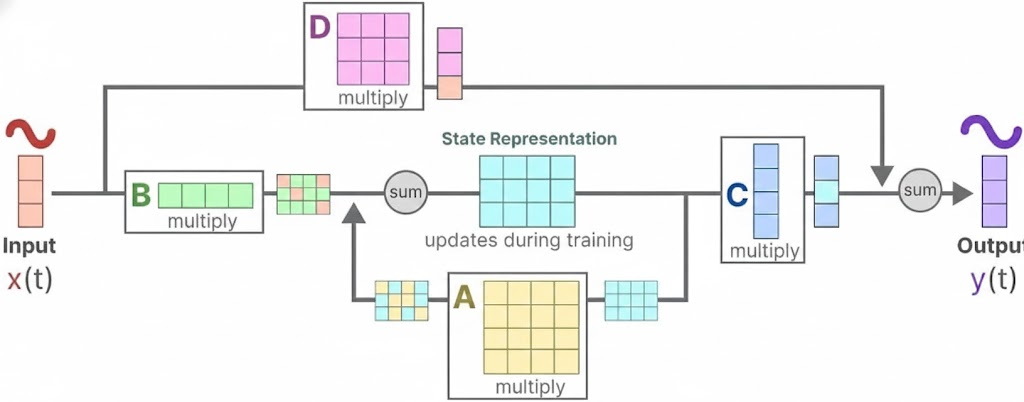
基于 Mamba (SSM) 架构的最新研究确实催生了许多创新的魔改版本,应用于不同的领域并带来了更多创新。例如,u-mamba 用于生物医学图像的分割任务,采用了混合 CNN-SSM 架构,能捕捉局部细粒度特征和长程依赖关系,具有自配置能力、线性扩展能力以及与其他技术集成的潜力;Weak-mamba-unet 是用于医学图像分割的弱监督学习框架,结合了 CNN、ViT 和 VMamba 的优势,采用多视角交叉监督学习方法;Graph-Mamba 是一种新型的图网络,将选择性状态空间模型 (SSM) 与图网络集成,实现了输入相关的节点过滤和自适应上下文选择,在大型图上能减少高达 74% 的 GPU 内存消耗;Swin-UMamba 则提出了用于 2D 医学图像分割的基于 Mamba 的网络及其变体结构,变体具有更少的参数和更低的 FLOPs,适用于高效应用,并且有效整合了基于 ImageNet 的预训练。
此外,Mamba 家族中还出现了如 VMamba(首个纯 SSM 骨干网络,解决了 Mamba 的方向依赖性,用于通用视觉)、VideoMamba(通过分解时空维度高效处理长序列,用于视频分类和行为识别)和 RecMamba(将 Mamba 引入序列推荐,捕捉用户动态偏好和长期依赖,用于推荐系统)等重要变体,共同展现了 Mamba 架构在处理长序列、实现线性扩展以及跨领域应用方面的强大潜力。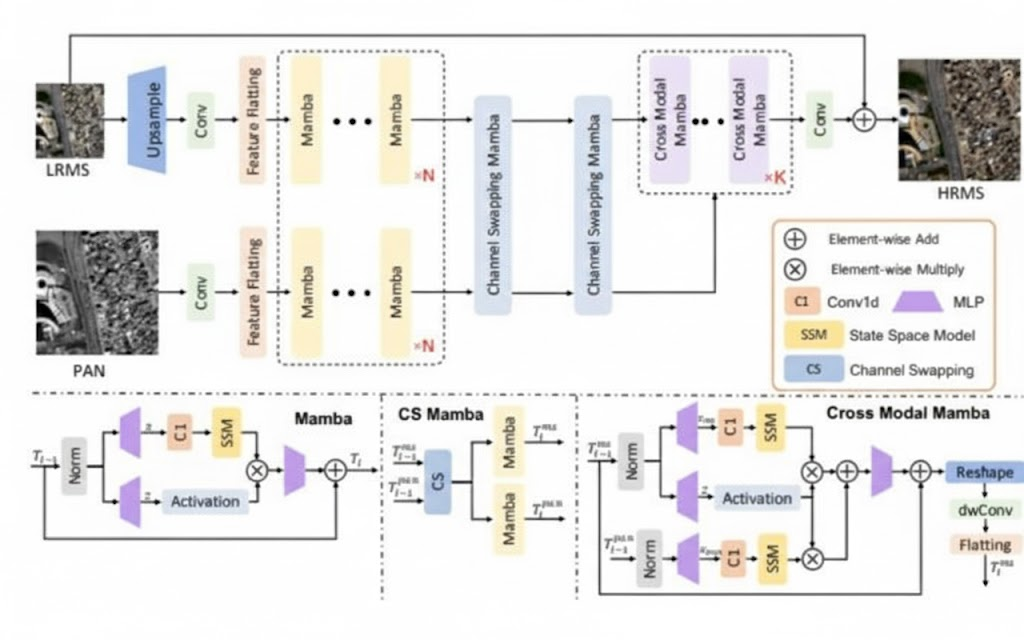
Mamba 是一种新的选择性结构状态空间模型,它的一些最新创新点包括:
- 简化的 SSM 架构:Mamba 将结构化状态空间序列模型(S4)中使用的类似线性注意力的块和多层感知器(MLP)块进行集成,构建了 Mamba 块。总体架构由重复的 Mamba 块与标准规范化层和残差连接交织组成。它继承了状态空间模型序列长度的线性可伸缩性,同时实现了类似于 Transformer 的建模能力。
- 选择机制:通过将其参数作为输入的函数,提高基于上下文的推理能力,利用一种选择机制,使其能够更高效和有效地捕获相关信息,特别是在处理长序列时。这种选择机制可以基于输入内容有选择性地传播或遗忘信息,过滤掉与问题无关的信息,并且可以长期记住与问题相关的信息。
- 硬件感知算法:设计了融合了内核和重新计算的硬件感知算法,避免了中间状态的存储,减少内存需求,提高计算效率。例如采用“并行扫描算法”而非“卷积”来进行模型的循环计算,为了减少 GPU 内存层次结构中不同级别之间的 I/O 访问,它没有具体化扩展状态。
若没有本文 Issue,您可以使用 Comment 模版新建。