
Mamba的前世今生
- RNN作为第一代序列模型,奠定了序列处理的基础;
- HiPPO作为理论框架,为RNN的长程依赖问题提供了数学上的最优记忆解决方案;
- S4将HiPPO的连续时间理论工程化,通过离散化处理使其能够处理实际中的离散序列数据,同时引入了可训练的参数矩阵;
- Mamba(S6)在S4基础上革新性地引入了动态选择性机制,使模型参数能够根据输入内容自适应调整,从而实现了接近注意力机制的内容感知能力,同时保持了线性计算复杂度。
RNN前文已经介绍过了,故这里不再过多介绍。下文将详细介绍从SSM到S4、S4D的升级之路
HiPPO:长距离依赖问题的解决之道
如我们之前在循环表示中看到的那样,矩阵
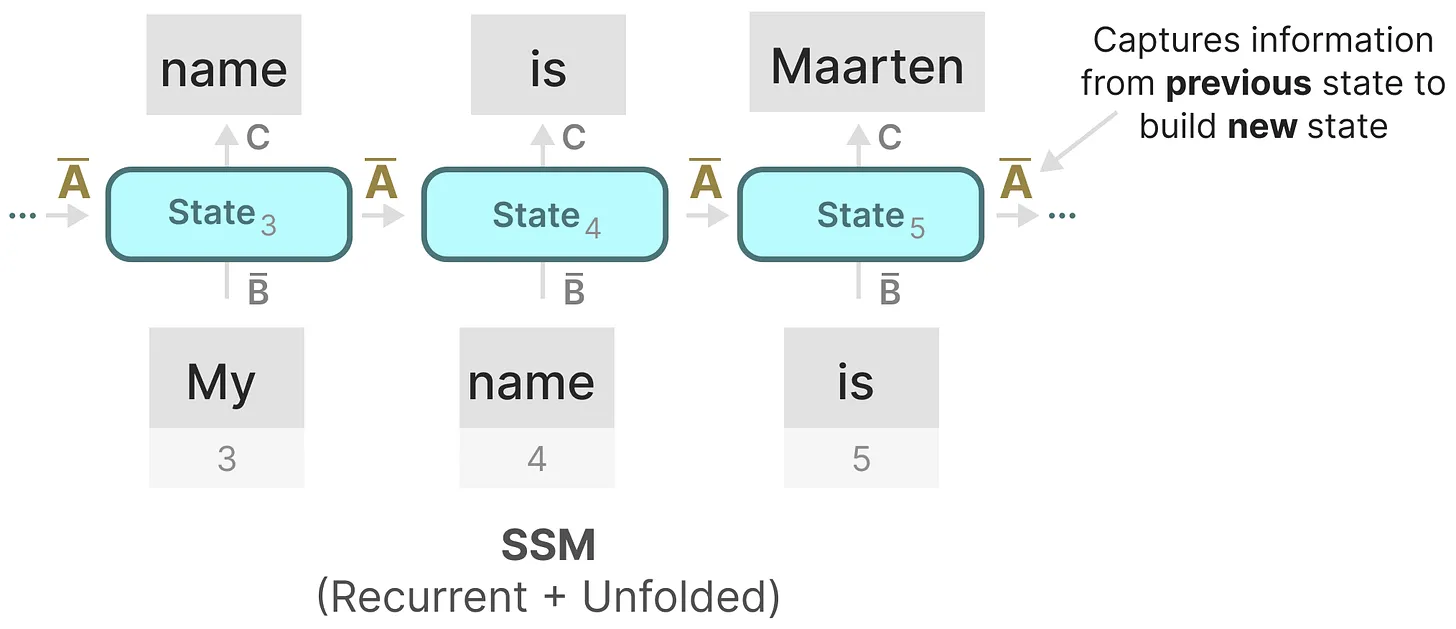
其实,某种意义上,算是矩阵
由于矩阵A只记住之前的几个token和捕获迄今为止看到的每个token之间的区别,特别是在循环表示的上下文中,因为它只回顾以前的状态。
那么我们怎样才能以保留比较长的memory的方式创建矩阵A呢?
答案是使用HiPPO
HiPPO尝试将当前看到的所有输入信号压缩为一个系数向量。
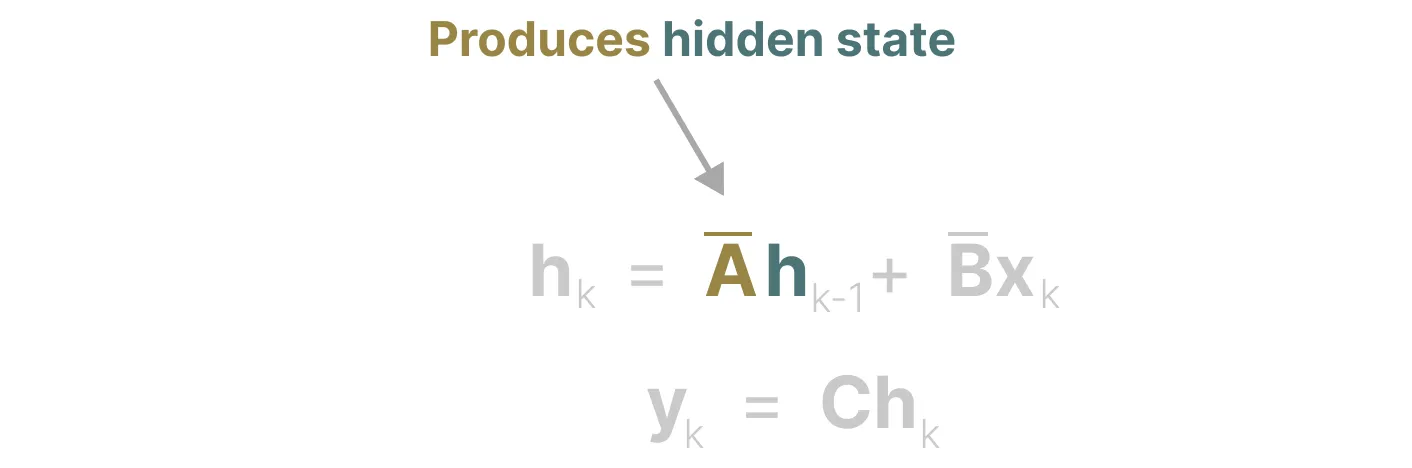
它使用矩阵构建一个“可以很好地捕获最近的token并衰减旧的token”状态表示,说白了, 通过函数逼近产生状态矩阵 A 的最优解,其公式可以表示如下
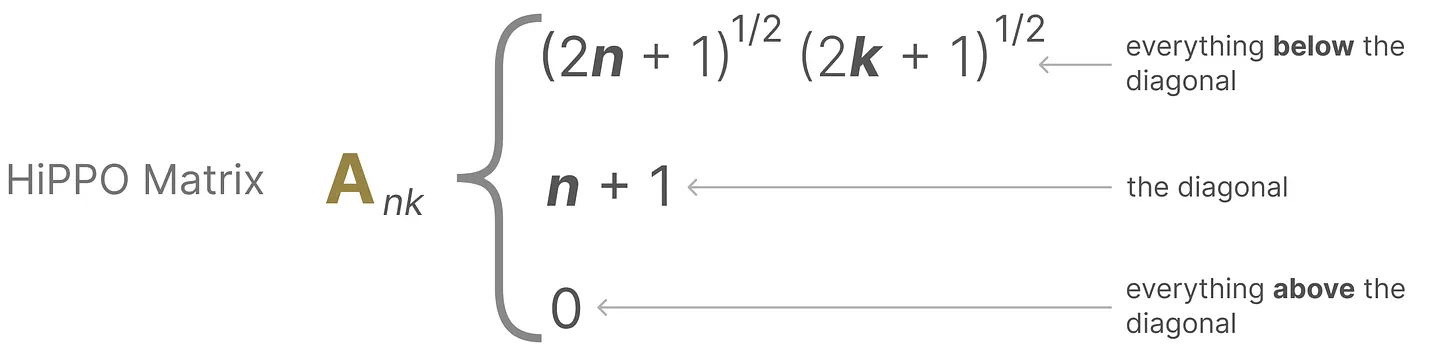
正由于HiPPO 矩阵可以产生一个隐藏状态来记住其历史(从数学上讲,它是通过跟踪Legendre polynomial的系数来实现的,这使得它能够逼近所有以前的历史),使得在被应用于循环表示和卷积表示中时,可以处理远程依赖性。
==补充:HiPPO的定义与推导==
基本形式
SSM建模所用的是线性ODE系统(线性常微分方程):
其中
我们可以从两个角度回答“为什么是线性系统”:
- 足够简单: 从理论上来说,线性化往往是复杂系统的一个最基本近似,所以线性系统通常都是无法绕开的一个基本点。
- 足够复杂: 只要
足够大,线性系统就可以通过指数函数和三角函数的组合来拟合足够复杂的函数,因此可以想象线性系统也有足够复杂的拟合能力。
HiPPO给出的结果更加本质:当我们试图用正交基去逼近一个动态更新的函数时,其结果就是如上的线性系统。这意味着HiPPO不仅告诉我们线性系统可以逼近足够复杂的函数,还告诉我们怎么去逼近,甚至近似程度如何。
有限压缩
这里只考虑
对于实际遇到的数据,我们通常更愿意使用在平方可积条件下的正交函数基展开,比如傅里叶(Fourier)级数。
在线函数逼近
由于实际中的
系数
线性初现
以
这表明,当我们试图用傅里叶级数去记忆一个实时函数的最邻近窗口内的状态时,结果自然而然地导致了一个线性ODE系统。
一般框架
标准正交基
设
这也被称为
勒让德多项式
HiPPO(High-order Polynomial Projection Operators)的关键是选取多项式为基。这里选取的是勒让德(Legendre)多项式
勒让德多项式的好处是==它是纯粹定义在实数空间==中的,相比傅里叶基,多项式的形式能够有助于简化部分
邻近窗口(LegT)
这是第一个例子,考虑只保留最邻近窗口的信息,此时映射
S4(ICLR 2022):综合SSM + 离散化(可循环表示或卷积表示) + HiPPO
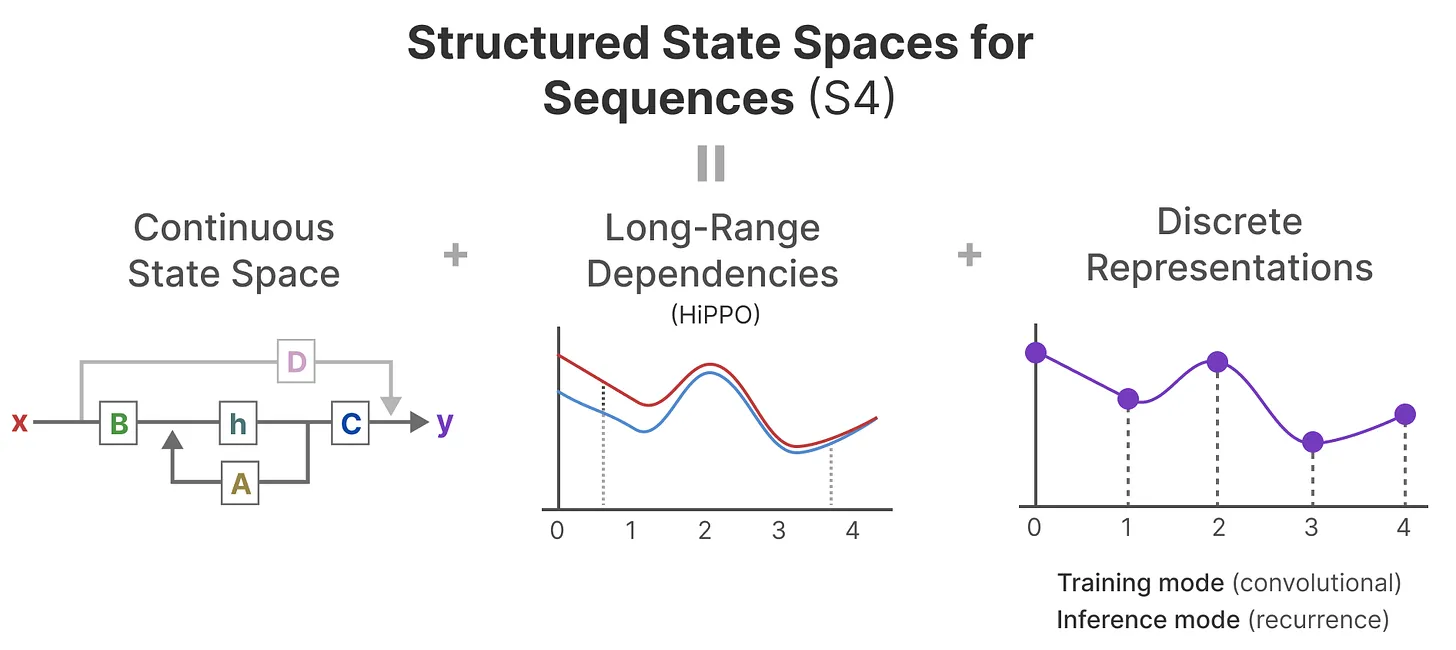
如上图所示,S4综合了上面所讲的:SSM + 离散化(可循环表示或卷积表示) + HiPPO
S4D(NeurIPS 2022):将参数矩阵标准化为对角结构
虽然Gu等人[21-Combining recurrent, convolutional, and continuous-time models with linear state space layers(NeurIPS 2021)]展示了基于SSM的模型在通过HiPPO初始化[18-Hippo(NeurIPS 2020)]处理长距离依赖方面的潜力
但实践中,为了提高实际可行性,S4D[On the Parameterization and Initialization of Diagonal State Space Models,Submitted on 23 Jun 2022 (v1),后中了NeurIPS 2022]建议将参数矩阵标准化为对角结构
如下图所示,S4D本质上就是一种对角线SSM,继承了S4的优点,但同时更加简单
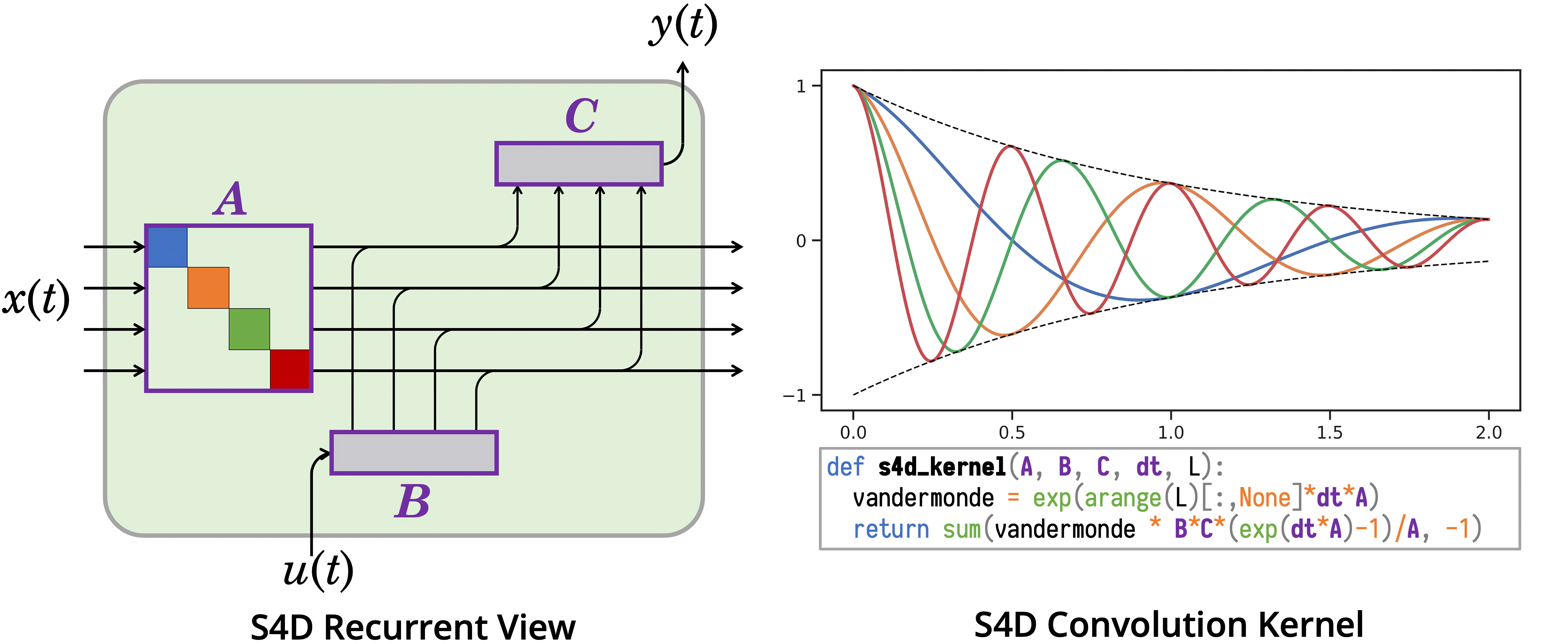
- 如上图左侧所示,当基于HiPPO的A矩阵变换为对角线结构之后,便使得其可以被视为一组一维SSM
- 如上图右侧所示,作为卷积模型,S4D具有简单且可解释的卷积核,可以用两行代码实现
颜色表示独立的一维SSM;紫色表示可训练参数「 Colors denote independent1-D SSMs;purple denotes trainable parameters」
关于S4D,这里也有对应的描述,且如下定理所示,所有的HiPPO矩阵都可以用一种特定的方式表示,这种方式叫做NPLR(非正定低秩)表示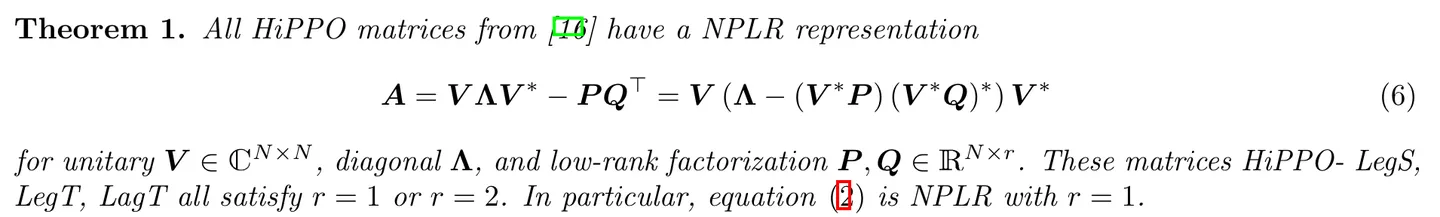
意味着矩阵A可以被分解成两部分:一部分是,另一部分是,其中
V是一个特殊的矩阵,它的列向量是相互垂直的(在数学上称为酉矩阵)
Λ是一个对角矩阵,意味着它只在主对角线上有元素
P和Q是低秩矩阵,意味着它们可以被表示为少数几个向量的乘积
此外,矩阵A还可以用另一种方式表示,即$V(Λ-(V^P)(V^Q)^)V^$,这实际上是对前面提到的分解的一种重新排列
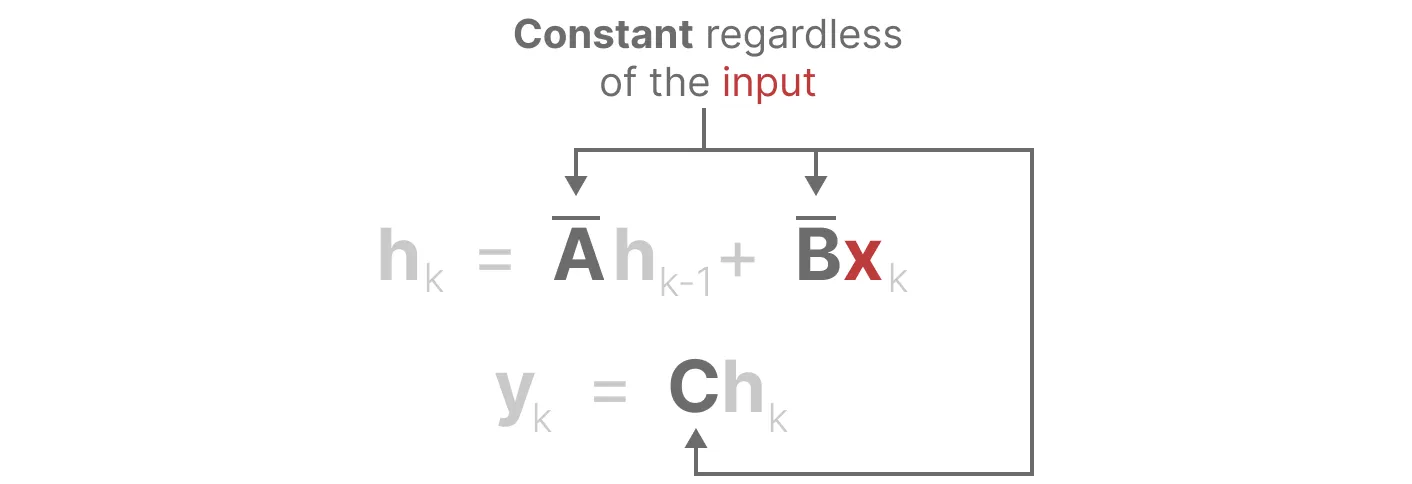
SSM的问题:矩阵不随输入不同而变化,无法针对输入做针对性推理
Linear Time Invariance规定 SSM中的A、B、C不因输入不同而不同
首先,Linear Time Invariance(LTI)规定 SSM中的A、B、C不随输入不同而不同。这意味着
对于 SSM 生成的每个token,矩阵A 、B、C都是相同的(regardless of what sequence you give the SSM, the values of A,B,and C remain the same. We have a static representation that is not content-aware)
使得SSM无法针对输入做针对性的推理「since it treats each token equally as a result of the fixed A, B, and C matrices. This is a problem as we want the SSM to reason about the input (prompt)」
此外,如下图所示,无论输入x 是什么,矩阵 B都保持完全相同,因此与x无关
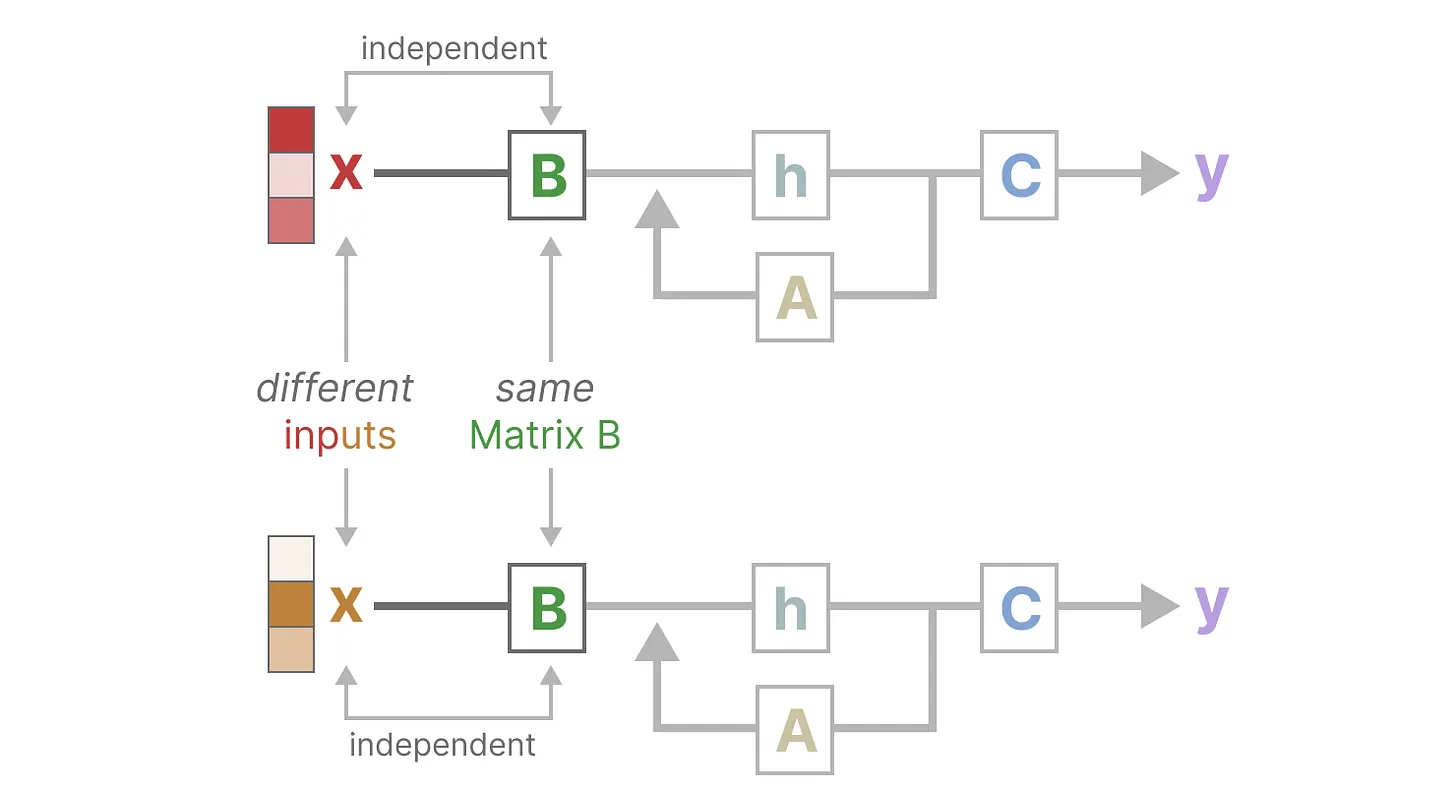
同样,无论输入如何,A和C也保持固定
如何改进S4以根据各个token重要性程度的不同而选择性聚焦的示例
比如 “I want to order a hamburger.”这句
如果没有选择性,S4会花费相同的“精力”来处理每个单词:
但如果是一个试图对这句话的意图进行分类的模型,它可能会想更多地“关注”order、hamburger,而不是want、to
如下图所示,而通过使模型参数成为输入的函数,模型就可以做到“专注于”输入中对于当前任务更重要的部分,而这正是mamba的创新点之一
凡事也有利有弊,虽然mamba可以“专注于”输入中对于当前任务更重要的部分,但坏处是没法再通过CNN做并行训练了,原因在于:
让我们回想一下之前计算的卷积核
在S4中,我们可以预先计算该内核、保存,并将其与输入相乘,因为离散参数 、 、 是恒定的 但在Mamba中,这些矩阵会根据输入而变化。因此,我们无法预计算,也无法使用CNN模式来训练我们的模型
下面这个式子当然也就用不上了
说白了,如果我们想要选择性,得用RNN模式进行训练(If we want selectivity, we’ll need to train with RNN mode),然偏偏RNN的训练速度非常慢;所以我们需要找到一种无需卷积的并行训练方式。
若没有本文 Issue,您可以使用 Comment 模版新建。