
Mamba的三大创新
- 对输入信息有选择性处理(Selection Mechanism)
- 硬件感知的算法(Hardware-aware Algorithm)
该算法采用“并行扫描算法”而非“卷积”来进行模型的循环计算(使得不用CNN也能并行训练),但为了减少GPU内存层次结构中不同级别之间的IO访问,它没有具体化扩展状态
当然,这点也是受到了S5(Simplified State Space Layers for Sequence Modeling)的启发- 更简单的架构
将SSM架构的设计与transformer的MLP块合并为一个块(combining the design of prior SSM architectures with the MLP block of Transformers into a single block),来简化过去的深度序列模型架构,从而得到一个包含selective state space的架构设计
选择性状态空间模型:从S4到S6
作者认为,序列建模的一个基础问题是把上下文压缩成更小的状态(We argue that a fundamental problem of sequence modeling is compressing context into a smaller state),从这个角度来看
Transformer的注意力机制虽然有效果但效率不算很高,毕竟其需要显式地存储整个上下文(storing the entire context,也就是KV缓存),直接导致训练和推理消耗算力大。
好比,Transformer就像人类每写一个字之前,都把前面的所有字+输入都复习一遍,所以写的慢RNN的推理和训练效率高,但性能容易受到对上下文压缩程度的限制
On the other hand, recurrent models are efficient because they have a finite state, implying constant-time inference and linear-time training. However, their effectiveness is limited by how well this state has compressed the context.好比,RNN每次只参考前面固定的字数(仔细体会这句话:When generating the output, the RNN only needs to consider the previous hidden state and current input. It prevents recalculating all previous hidden states which is what a Transformer would do),写的快是快,但容易忘掉更前面的内容
而SSM的问题在于其中的矩阵A B C不随输入不同而不同,即无法针对不同的输入针对性的推理
最终,Mamba的解决办法是,相比SSM压缩所有历史记录,mamba设计了一个简单的选择机制,通过“参数化SSM的输入”,让模型对信息有选择性处理,以便关注或忽略特定的输入
这样一来,模型能够过滤掉与问题无关的信息,并且可以长期记住与问题相关的信息
好比,Mamba每次参考前面所有内容的一个概括,越往后写对前面内容概括得越狠,丢掉细节、保留大意。
为方便对比,我再用如下表格总结下各个模型的核心特点
| 模型 | 对信息的压缩程度 | 训练的效率 | 推理的效率 | 备注/核心机制 |
|---|---|---|---|---|
| Transformer (注意力机制) | 不对历史记录压缩,对每个历史记录都保持关注。 | 训练消耗算力大,但可并行计算。 | 推理消耗算力大,因为自回归推理需要重复计算注意力分数。 | 并行训练,但推理慢。在多个查询-键对上并行执行矩阵乘法。 |
| RNN | 随着时间的推移,往往会忘记一部分信息,在提取长距离动态方面能力有限。 | RNN 没法并行训练,因为每个时间步骤都依赖于前一个。 | 推理时只看一个时间步,推理高效 (自回归推理过程中快速输出)。 | 推理快但训练慢。在非线性递归框架内运作。 |
| CNN | - | 训练效率高,可并行,通过创建一组卷积核实现卷积形式的并行训练。 | 推理不如 RNN 快速,因为内核大小固定。 | 将 SSM 表示为卷积计算可以实现并行训练。 |
| SSM (状态空间模型) | 压缩每一个历史记录,通过一组隐藏变量(状态 |
离散 SSM 支持并行训练,因为其线性属性支持卷积计算。 | 离散 SSM 支持递归推理,具有类似于 RNN 的结构。 | 兼具并行训练和高效推理。传统 SSM 是时间不变的,限制了上下文感知建模。 |
| Mamba | 引入选择性机制,选择性地关注必须关注的、过滤掉可以忽略的。 每次参考前面所有内容的一个概括。 | 兼备训练效率,通过硬件感知算法和递归扫描优化性能,加速高达 3 倍。 | 兼备推理效率,通过递归操作实现计算成本的线性或近线性扩展。 | 近线性可扩展性;动态选择性 SSM 架构,解决了传统 SSM 缺乏上下文感知的问题。 |
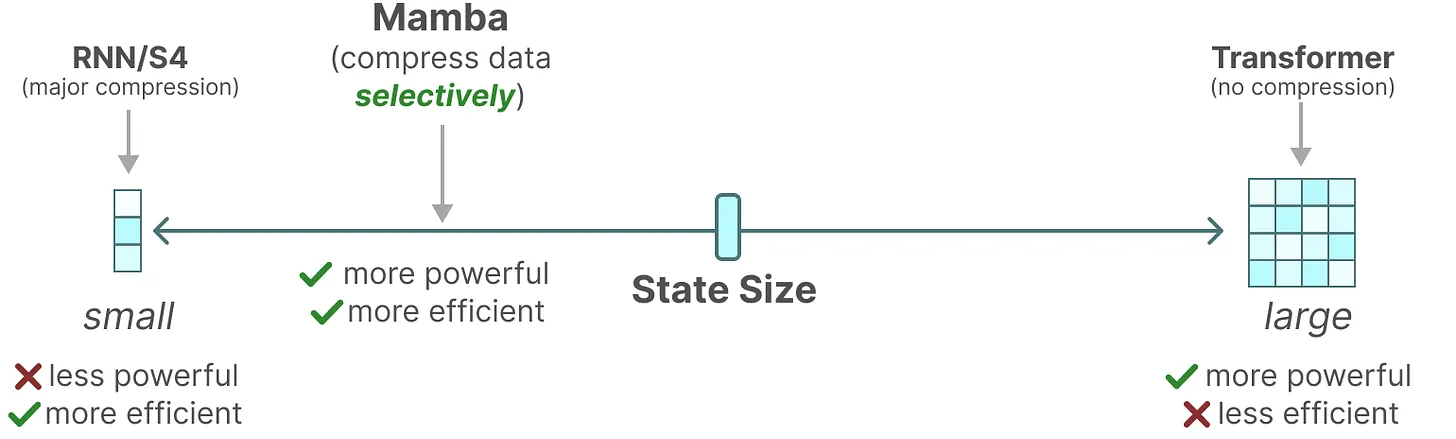
总之,序列模型的效率与效果的权衡点在于它们对状态的压缩程度:
高效的模型必须有一个小的状态(比如RNN或S4)
而有效的模型必须有一个包含来自上下文的所有必要信息的状态(比如transformer)
而mamba为了兼顾效率和效果,选择性的关注必须关注的、过滤掉可以忽略的
为方便理解,下面将再进一步阐述mamba与其前身结构化空间模型S4相比的优势
S4的4个参数的不随输入不同而不同
首先,在其前身S4中,其有4个参数(∆, A B, C)
且它们不随输入变化(即与输入无关),这些参数控制了以下两个阶段

第一阶段(1a 1b),通常采用固定公式
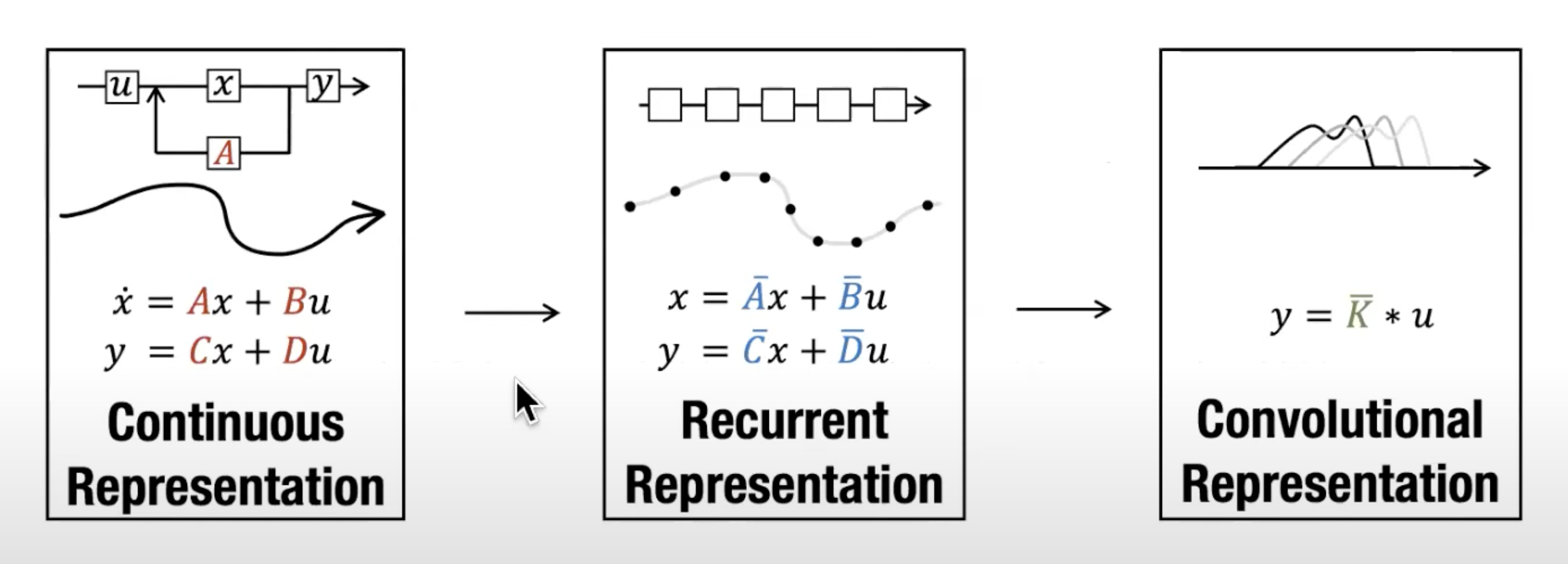
和 ,将“连续参数” 转化为“离散参数” ,其中 称为离散化规则,且可以使用多种规则来实现这一转换;例如下述方程中定义的零阶保持(ZOH) , 第二阶段(2a 2b,和3a 3b),在参数由变换为后,模型可以用两种方式计算,即线性递归(2)或全局卷积(3)
如之前所说的S4模型通常使用卷积(3)进行高效的并行化训练(模型可以提前看到整个输入序列),并切换到RNN模式(2)以高效的自回归推理(每次输入只看到一个时间步)
S4可以做高效的并行化训练的原因就是卷积模式能够绕过状态计算,并实现仅包含(B, L, D)的卷积核(3a)
S4中三个矩阵的维度表示、维度变化
通过之前的讲解,可知矩阵都可以由
个数字表示(the A ∈ ℝ𝑁×𝑁, B ∈ ℝ𝑁×1 , C ∈ ℝ1×𝑁 matrices can all be represented by 𝑁 numbers.)
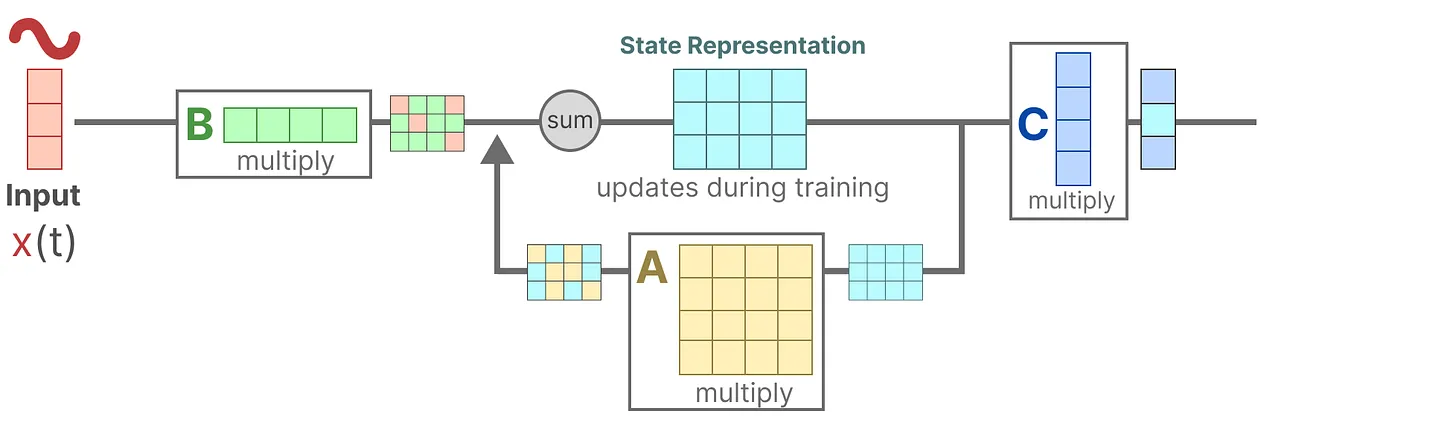
mamba:从S4到S6的算法变化流程
硬件感知的设计:并行扫描(parallel scan)且借鉴Flash Attention
如之前所述,由于A B C这些矩阵现在是动态的了,因此无法使用卷积表示来计算它们(CNN需要固定的内核),因此,我们只能使用循环表示,如此也就而失去了卷积提供的并行训练能力
so,为了实现并行化,接下来,探讨如何使用循环计算输出『为免歧义,提前说一嘴,这里的循环计算非RNN表示的计算,而是特指下文即将提到的——“并行扫描算法”parallel scan algorithm。并行扫描算法是一种允许在保持循环计算特性的同时,对序列数据进行并行处理的技术。这种方法可以在处理序列时,对序列的各个部分同时进行计算——而不是一个接一个地处理,从而实现并行化』
每个状态比如
都是前一个状态比如 乘以 ,加上当前输入 乘以 的总和,这就叫扫描操作(scan operation),可以使用 for 循环轻松计算,然这种状态之下想并行化是不可能的(因为只有在获取到前一个状态的情况下,才能计算当前的每个状态) 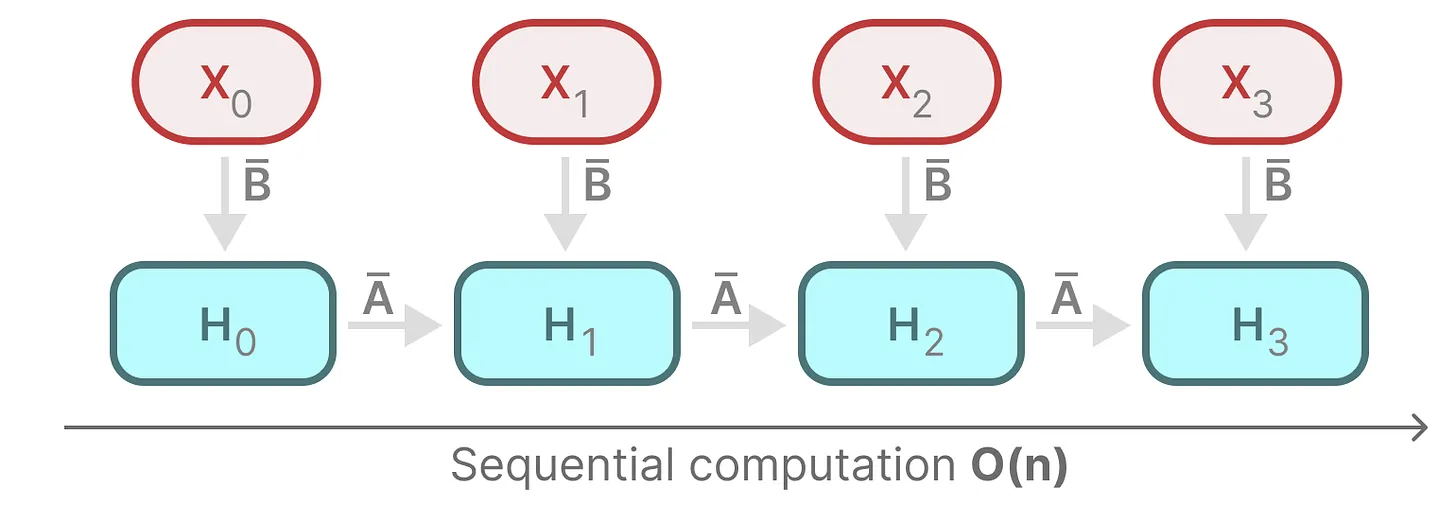
mamba通过并行扫描(parallel scan)算法使得最终并行化成为可能
其假设我们执行操作的顺序与关联属性无关
因此,可以分段计算序列并迭代地组合它们,即动态矩阵B和C以及并行扫描算法一起创建:选择性扫描算法(selective scan algorithm)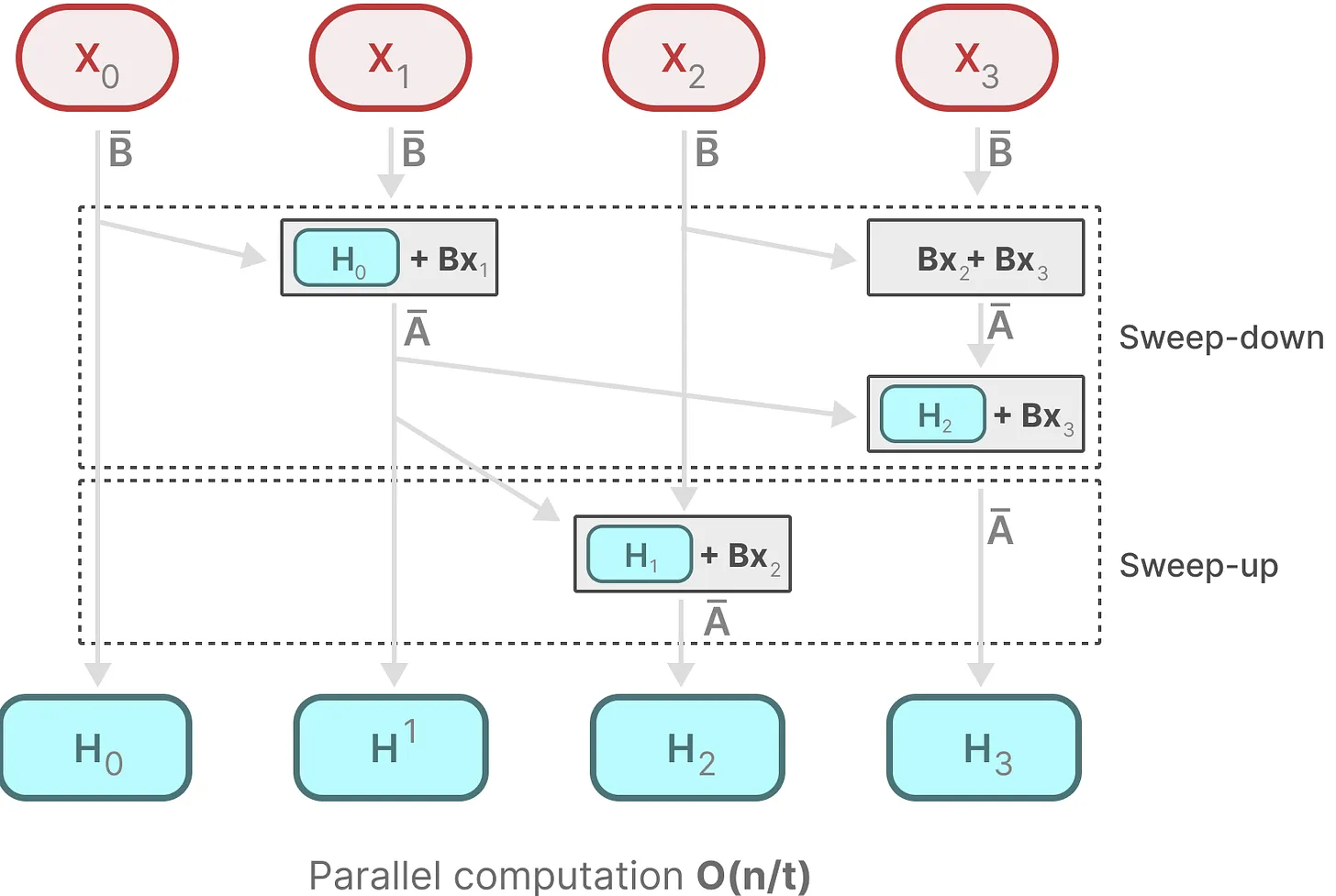
接下来,关键来了,我们再仔细研究下==各个变量的含义及其与所谓门控之间的联系==(顺带帮你一针见血的指出如果各个变量变成可变的会发生什么)
,类似遗忘门
如sonta所说,这个量跟RNN里的gating有着深刻的联系(∆ in SSMs can be seen to play a generalized role of the RNN gating mechanism)
即data dependent的 Δ 跟RNN的forget gate的功能类似(step size Δ that represents the resolution of the input discretization of SSMs is the principled foundation of heuristic gating mechanisms)啥意思呢,如mamba作者回复审稿人的一段话所说,“In general, controls the balance between how much to focus or ignore the current input . It is analogous to the role of the gate in Theorem 1, mechanically, a large resets(重置) the state and focuses on the current input , while a small persists(保持) the state and ignores the current input ”。相当于大则关注,小则忽略
说白了,较小的步长Δ会忽略当前输入,而更多地使用先前的上文,而较大的步长Δ会更多地关注当前输入而不是上文
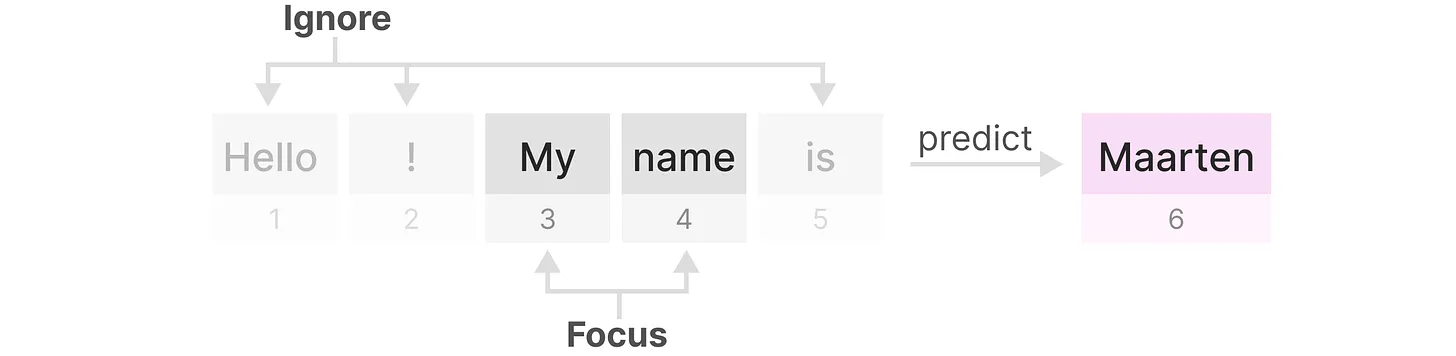
总之,如果某个输入比较重要 它的步长就更长些,被重点关注;如果某个输入不太重要 它的步长就短,被直接忽略.从而对于不同的输入,达到选择性关注或忽略的目标,做到详略得当 主次分明
,起到的作用类似于:进RNN的memory ,起到的作用类似于:取RNN的memory
总之,修改B和C可以允许模型更精细地控制是否让输入x进入状态 h,或状态h进入输出 y,所以 B 和 C 类似于 RNN 中的输入门和输出门(如mamba论文中所说,modifying B and C to be selective allows finer-grained control over whether to let an input 𝑥𝑡 into the state ℎ𝑡 or the state into the output 𝑦𝑡)咋理解?我拿出上文第二部分的这个图 一摆,就一目了然了
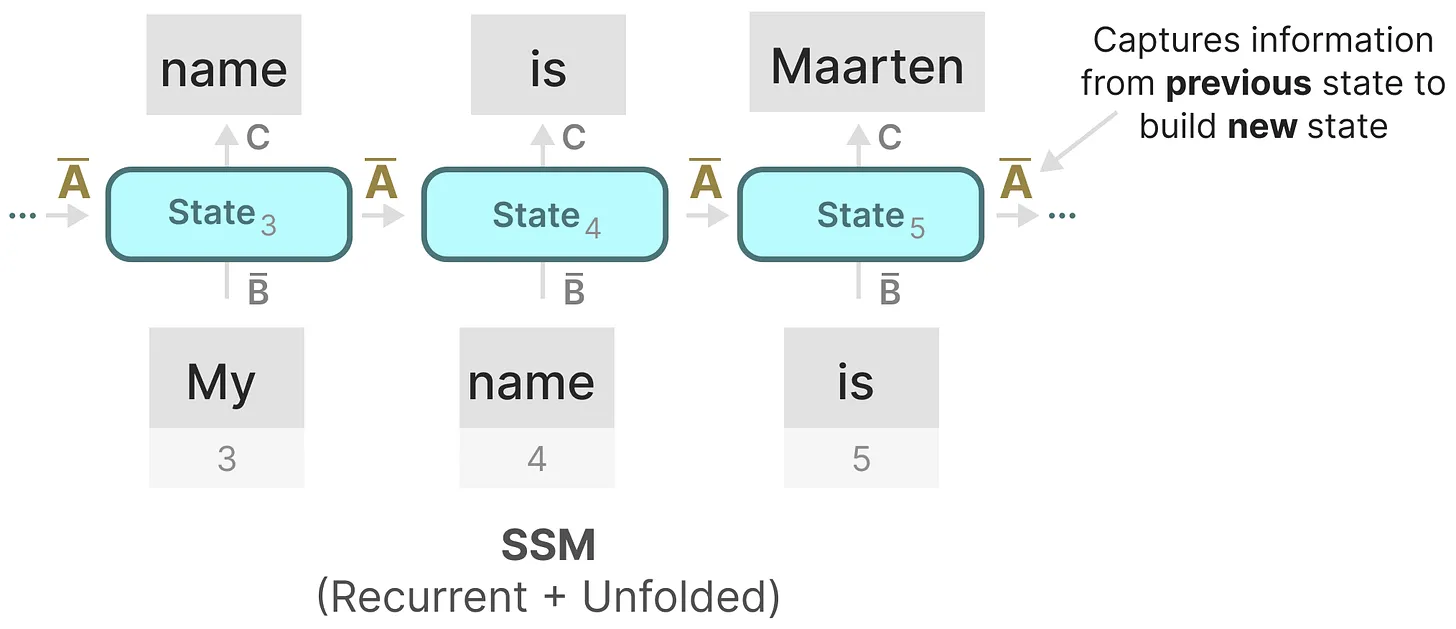
所以有人说,data dependent的
意味着对应这个维度的SSM来说,A在每个hidden state维度上的作用可以不相同,起到multi-scale/fine-grained gating的作用,这也是LSTM网络里面用element-wise product的原因
总之,Mamba通过合并输入的序列长度和批量大小来使矩阵B和C,甚至步长Δ取决于输入(其意味着对于每个输入token,现在有不同的B和C矩阵,可以解决内容感知问题),从而达到选择性地选择将哪些内容保留在隐藏状态以及忽略哪些内容的目标
简化的SSM架构及最终的整体流程(含为何SSM之前有个CNN)
将大多数SSM架构比如H3「对应论文为:Hungry hungry hippos: Towards language modeling with state space models,Submitted on 28 Dec 2022 (v1)」的基础块,与现代神经网络比如Transformer中普遍存在的Gated MLP相结合,组成新的Mamba块,然后重复这个块(且与归一化和残差连接结合),便构成了Mamba架构
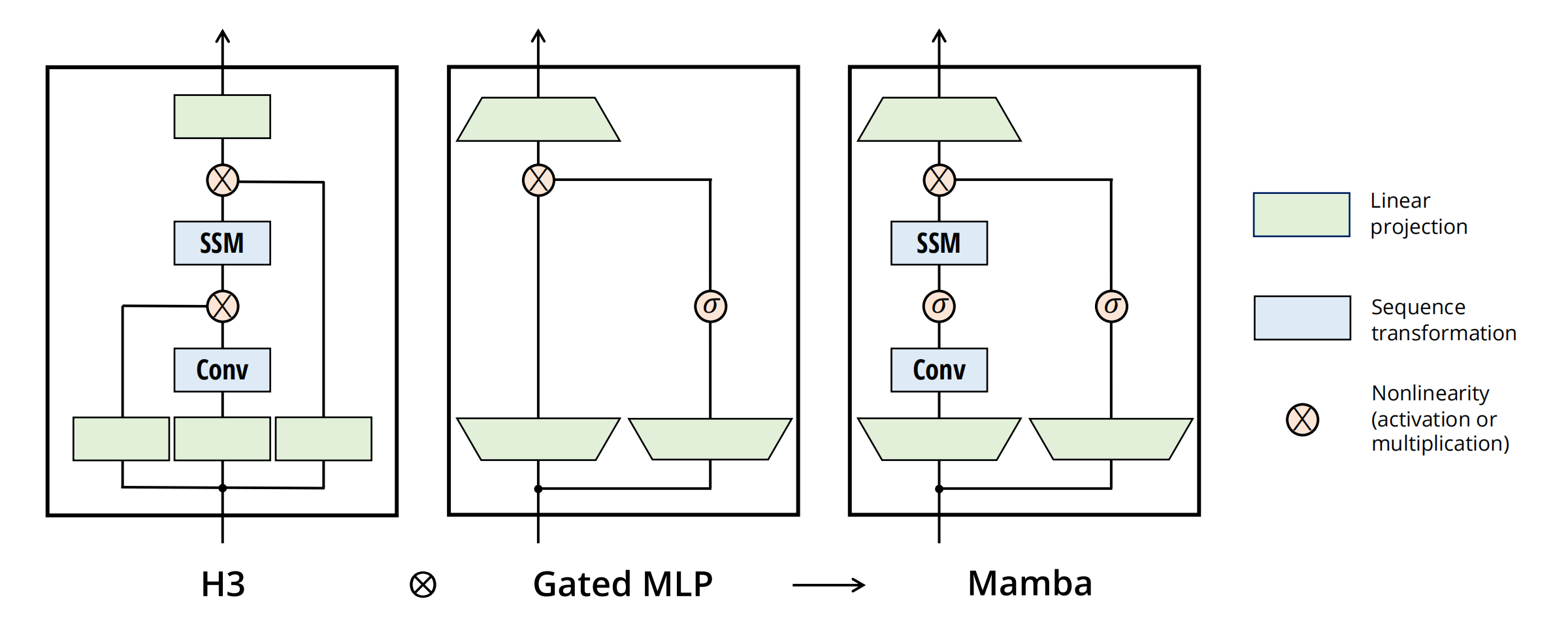
顺带提一嘴,transformer quality in linear time以及mega moving average equipped gated attention的这两个工作,也用了类似的结构:即删除transformer的ffn/glu结构
此外,关于mamba的整体架构,有两点值得强调下(特别是第二点,好几个读者留言提出了疑问)
- 为何要做线性投影
经过线性投影后,输入嵌入的维度可能会增加,以便让模型能够处理更高维度的特征空间,从而捕获更细致、更复杂的特征- 为什么SSM前面有个卷积?
本质是对数据做进一步的预处理,更细节的原因在于:
- SSM之前的CNN负责提取局部特征(因其擅长捕捉局部的短距离特征),而SSM则负责处理这些特征并捕捉序列数据中的长期依赖关系,两者算互为补充
- CNN有助于建立token之间的局部上下文关系,从而防止独立的token计算
毕竟如果每个 token 独立计算,那么模型就会丢失序列中 token 之间的上下文信息。通过先进行卷积操作,可以确保在进入 SSM 之前,序列中的每个 token 已经考虑了其邻居 token 的信息。这样,模型就不会单独地处理每个 token,而是在处理时考虑了整个局部上下文。
若没有本文 Issue,您可以使用 Comment 模版新建。