
序言
考虑一个很长的一维序列,当我们希望模型具有 “记忆” 能力的时候,我们实际上期望模型能在当前时间步对很久以前的时间步上的数据点具有无损恢复的能力。然而,模型的大小是不可能随序列长度增长的,也就是说我们需要使用有限的参数恢复出无限多时间步的数据点。
很显然无损恢复是不可能的。但是,我们可以用一种具有渐进收敛性的方法,尽可能减少这种损失。我们面临的第一个问题就是,怎样描述这个损失?一个非常自然的想法是直接把我们恢复出来的数据点和真实的数据点的距离求 L2 范数。Naive 的 L2 范数假设了所有历史数据点是同等重要的。
到这里,我们起码有了一种最简单的求损失的方法。如果我们把所有真实数据点看作对时间步的函数,那么我们上面求损失的过程正是函数逼近的过程,即我们不知道真实函数的表达式,但我们获取了它的若干采样数据点,我们可以依赖这些数据点,选取一个已知表达式的函数来逼近它。这个用于逼近的函数包含有限多的待优化的参数,而参数的数量不随序列长度变化。
1. 核心思想
HiPPO 提供了一个数学框架,通过将输入信号
核心机制:
- 投影 (Projection):将过去的所有输入信号投影到由正交多项式构成的系数空间。
- 在线更新 (Online Update):随着新输入
的到来,实时更新这些系数,而无需重新计算整个历史。
2. 数学框架
HiPPO 的核心是一个线性时不变系统 (LTI):
其中:
为存储记忆的系数向量。 为输入信号。 和 是预先定义的矩阵。
LegS (Legendre Measures)
对于 Legendre 度量(给予历史信息相同的权重),其
3. 离散化 (Discretization)
为了在计算机中处理,需要将连续的微分方程转化为离散的递归形式。通常采用 双线性变换 (Bilinear Transform):
离散化公式:
4. 架构模型实现
根据不会魔法的小圆的博客中的架构设计,HiPPO 作为一个记忆单元嵌入到Gated RNN的递归结构中: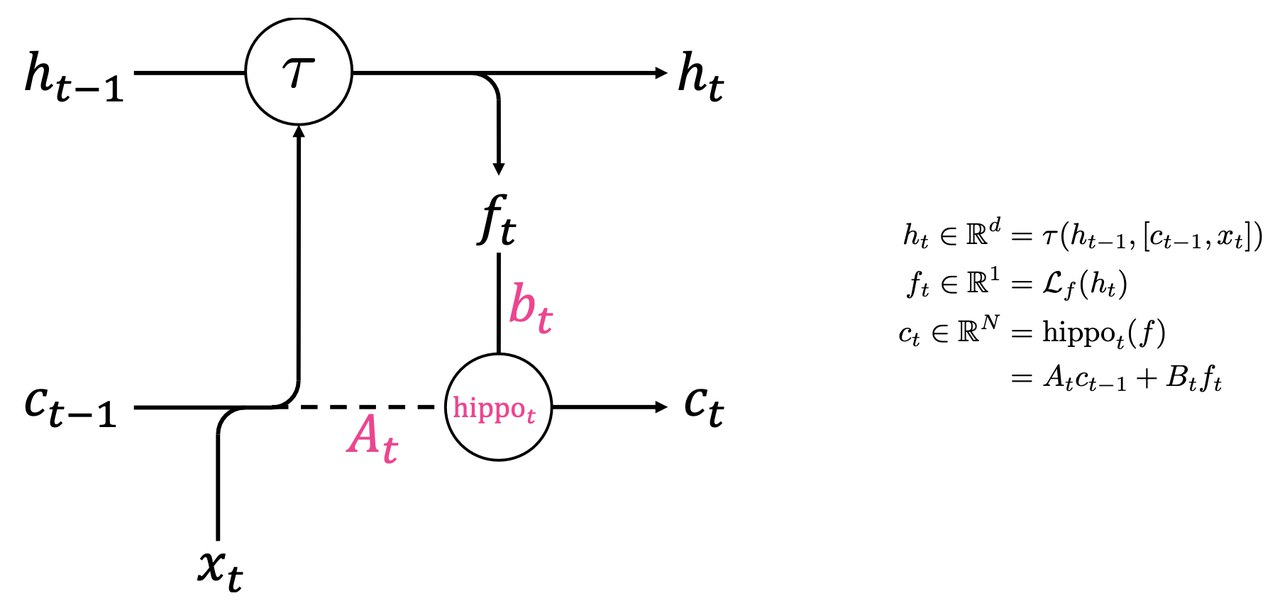
更新步骤:
融合输入:
可以是普通的 RNN 单元或 GRU。 它整合了当前输入
和来自 HiPPO 的长短期记忆 。
生成投影信号:
- 从当前的隐藏状态中提取关键信息。
更新 HiPPO 记忆:
- 利用固定的 HiPPO 矩阵将信号
压缩进记忆空间。
- 利用固定的 HiPPO 矩阵将信号
5. 代码实现 (PyTorch)
HiPPO 矩阵生成
1 | # 1. HiPPO 核心逻辑实现 |
混合模型前向传播
1 | # --- 根据图片架构实现的新模型 --- |
随机函数逼近可视化
1 | # --- 实验设置 --- |
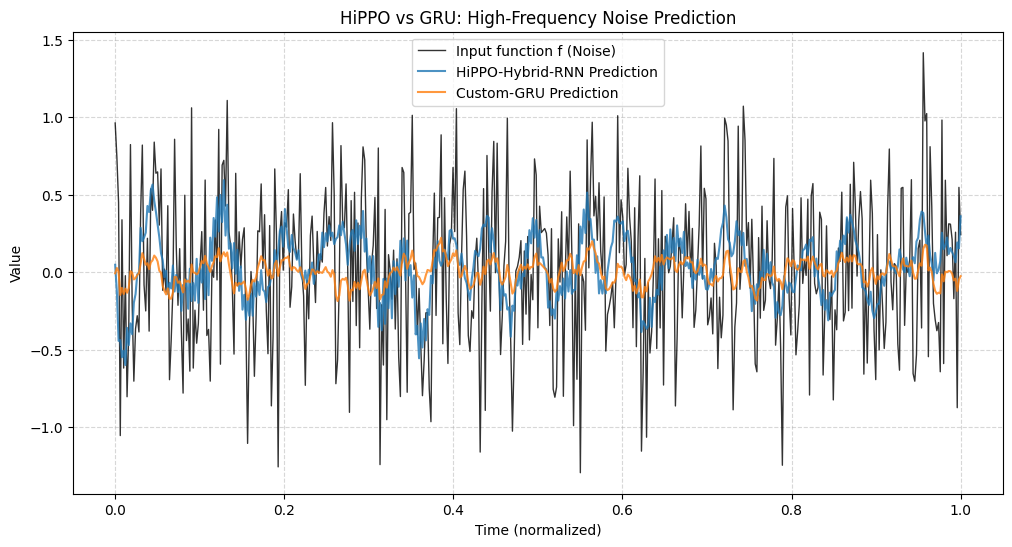
6. 总结
HiPPO 的优势在于其数学确定性。通过将 A 和 B 矩阵初始化为 LegS 形式并保持冻结,模型被赋予了一个“内置”的正交投影机制,这使得它在处理超长序列(如几千个时间步)时比单纯学习权重的 RNN 更加稳健。
若没有本文 Issue,您可以使用 Comment 模版新建。