
Mamba的基础知识
Mamba与循环框架的循环神经网络(RNNs)、并行计算和Transformer的注意力机制以及状态空间模型(SSMs)的线性属性密切相关。因此,本节旨在介绍这三种突出架构的概述。
RNN
RNNs在处理序列数据方面表现出色,因为它们能够保留内部记忆。这类网络在涉及分析和预测序列的众多任务中表现出显著的有效性,例如语音识别、机器翻译、自然语言处理和时间序列分析。为了掌握循环模型的基础,本节将提供标准RNN公式的简要概述。
具体来说,在每个离散时间步
隐藏状态充当网络的内存,并保留有关它所见过去输入的信息。这种动态内存允许RNN处理不同长度的序列。正式地,它可以写成
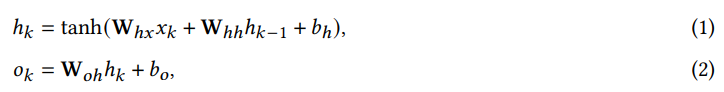
其中:
是负责将模型输入处理成隐藏状态的权重矩阵; 是隐藏状态之间的递归连接权重矩阵; 表示用于从隐藏状态生成输出的权重矩阵; 和 分别对应隐藏层和输出层的偏置项; 表示引入非线性到 RNN 模型的双曲正切激活函数。
换句话说,RNN 是非线性递归模型,通过利用隐藏状态中存储的历史知识有效地捕获时间模式。
然而,RNNs有几个局限性。首先,RNNs在有效提取输入序列中的长距离动态方面能力有限。随着信息通过连续的时间步骤传播,网络中权重的重复乘法可能导致信息的稀释或丢失。因此,对于RNNs来说,在进行预测时保留和回忆早期时间步骤的信息变得具有挑战性。其次,RNNs以增量方式处理序列数据,限制了它们的计算效率,因为每个时间步骤都依赖于前一个。这使得并行计算对于它们来说很困难。此外,传统的RNNs缺乏内置的注意力机制,这允许网络捕获输入序列中的全局信息。这种注意力机制的缺失限制了网络选择性地建模数据的关键部分的能力。为了克服这些限制,Transformer和状态空间模型出现了,每种方法都从不同的角度解决了这些挑战。这些两种方法将在后续的小节中进一步阐述。
Transformers
Transformer是深度学习领域的开创性模型,彻底改变了各种AI应用。它的引入标志着与传统序列到序列模型的显著偏离,通过采用自我注意力机制,促进了对模型输入中全局依赖性的捕获。例如,在自然语言处理中,这种自我注意力能力允许模型理解序列中不同位置之间的关系。
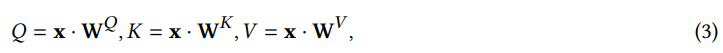
这样的程序然后通过Softmax函数传递,以标准化分数

除了执行单个注意力函数外,多头注意力被引入以增强模型捕获不同类型关系的能力,并为输入序列提供多种视角。在多头注意力中,输入序列并行通过多个自注意力模块进行处理。每个头独立操作,执行与标准自注意力机制完全相同的计算。然后,每个头的注意力权重被结合起来,创建值向量的加权和。这个聚合步骤允许模型利用来自多个头部的信息,并捕获输入序列中的多样化模式和关系。
数学上,多头注意力计算如下:
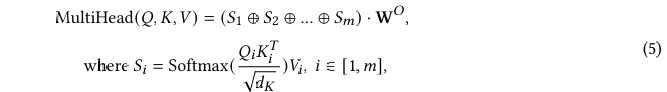
其中m是注意力头的数量,⊕是连接操作,
状态空间模型
状态空间模型(SSMs)是一种传统的数学框架,用于描述系统随时间的动态行为。近年来,SSMs在控制理论、机器人技术和经济学等多个领域中发现了广泛的应用。在其核心,SSMs通过一组隐藏变量,即“状态”,来体现系统的行为,使其能够有效地捕获时间数据依赖性。与RNNs不同,SSMs是线性模型,具有关联属性。具体来说,在经典的状态空间模型中,制定了两个基本方程,即状态方程和观测方程,通过当前时间t的N维隐藏状态ℎ( ) ∈ R 来模拟输入 ( ) ∈ R和输出 ( ) ∈ R之间的关系。该过程可以写成
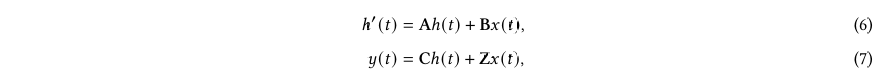
其中ℎ′( ) 是当前状态ℎ( )的导数,A ∈ R × 是描述状态如何随时间变化的状态转移矩阵,B ∈ R ×1是控制输入如何影响状态变化的输入矩阵,C ∈ R1× 表示基于当前状态生成输出的输出矩阵,D ∈ R表示决定输入如何直接影响输出的命令系数。一般来说,大多数SSMs在观测方程中省略了第二项,即,设置D ( ) = 0,这可以被认为是深度学习模型中的跳跃连接。
离散化。
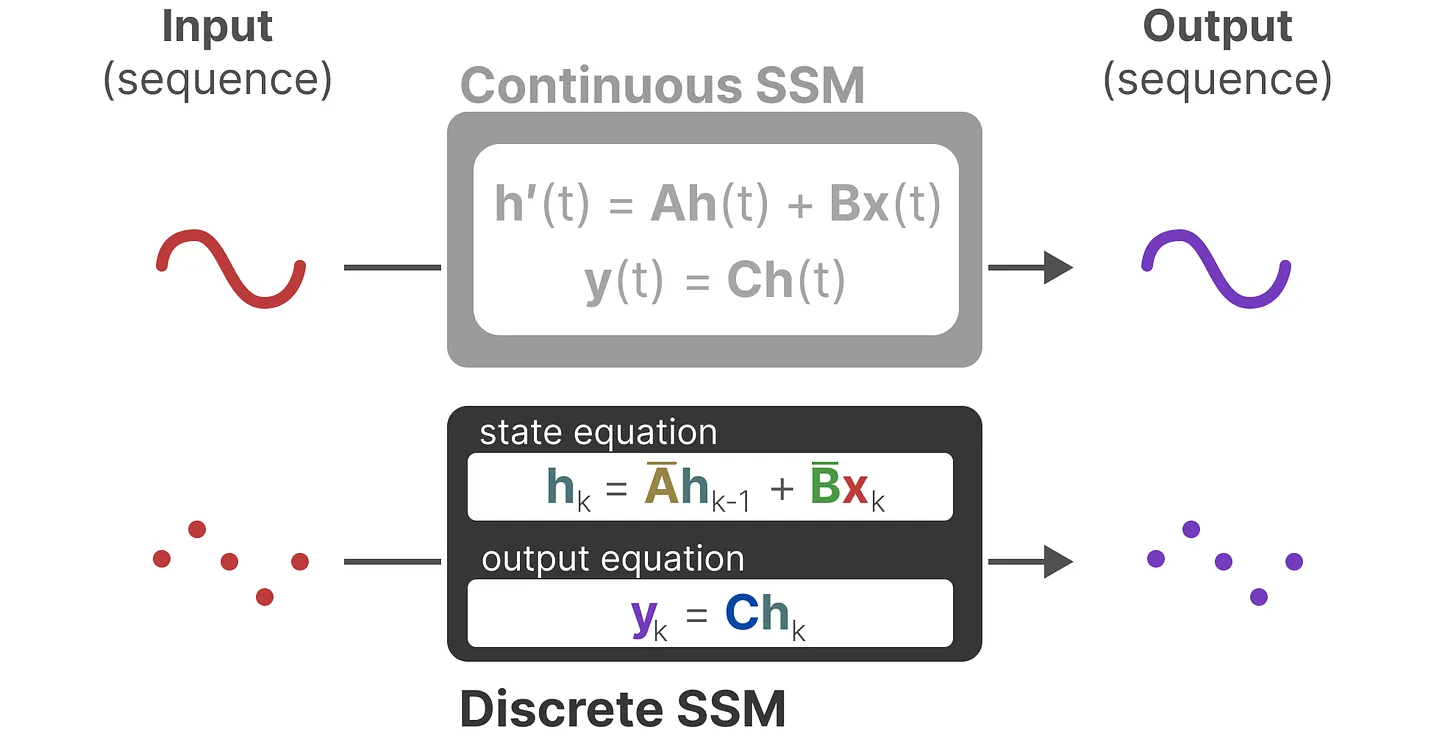
为了符合机器学习设置对各种现实世界场景的要求,SSMs必须经历一个离散化过程,将连续参数转换为离散参数。离散化方法通常旨在将连续时间划分为 n个具有相等积分区域的离散间隔。为了实现这一目标,作为最具代表性的解决方案之一,零阶保持(ZOH)成功地应用于SSMs,它假设函数值在间隔Δ = [ −1, ]内保持恒定。在ZOH离散化之后,SSM方程可以重写为
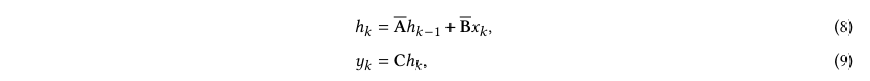
其中
零阶保持(ZOH)
zero order hold 只是微分方程
方法 1:微分极限法
首先根据导数定义
所以上述式子可变为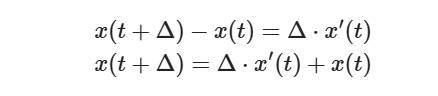
代入状态方程可得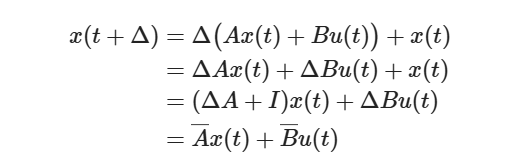
方法2:双线性变换
法一中使用了微分的思想,法2将尝试使用积分的思想。对f(x),其
代入状态方程,有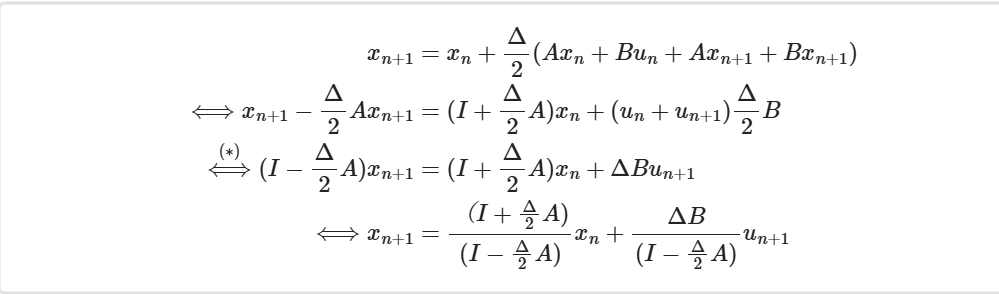
在极小的时间间隔
方法3:零序保持
法1和法2分别使用了微分和积分的思想。我们在法3中将使用常微分方程的方式求解。对
不妨假设
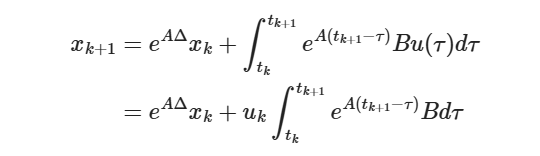
故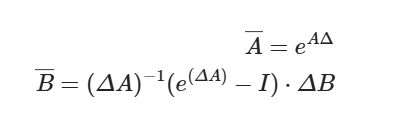
卷积计算。
作为线性系统,离散SSM具有关联属性,因此可以无缝集成到卷积计算中。更具体地说,它可以独立地计算每个时间步的输出,如下所示:
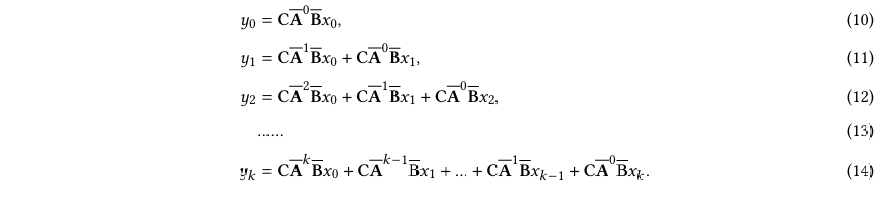
通过创建一组卷积核s K = (CB, …, CA B, …),递归计算可以转换为卷积形式:

其中x = [ 0, 1, …]和y = [ 0, 1, …] ∈ R L分别表示输入和输出序列,而 是序列长度。在这个情况下,输入矩阵B ∈ R × ,输出矩阵C ∈ R × ,和命令矩阵D ∈ R × ,而状态转移矩阵保持不变,即A ∈ R × 。
RNN、Transformer和SSM之间的关系。
图2描述了循环神经网络(RNN)、Transformer和状态空间模型(SSM)的计算算法。
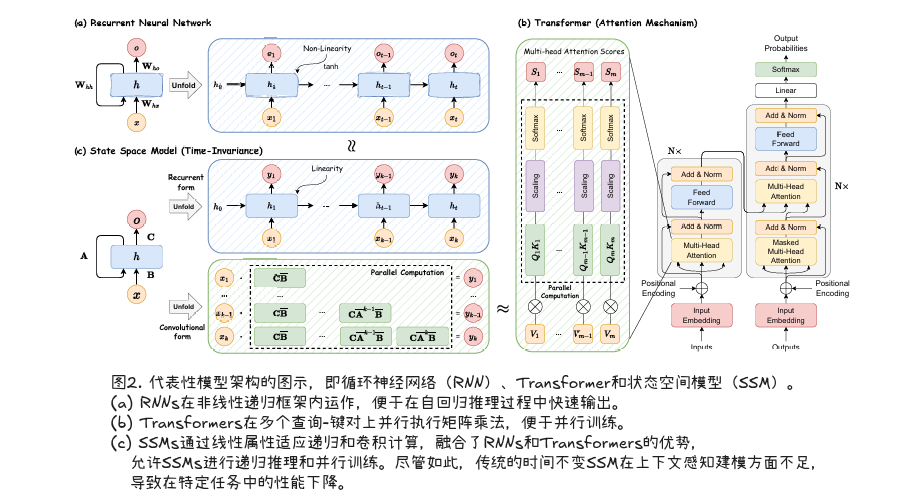
一方面,传统的RNN在非线性递归框架内运作,每个计算仅依赖于前一个隐藏状态和当前输入。虽然这种格式允许RNN在自回归推理过程中快速生成输出,但它阻碍了它们充分利用GPU并行计算,导致模型训练速度变慢。另一方面,Transformer架构在多个查询-键对上并行执行矩阵乘法,可以有效地跨硬件资源分布,从而加快了基于注意力模型的训练。然而,当从基于Transformer的模型生成响应或预测时,推理过程可能会很耗时。例如,语言模型的自回归设计需要顺序生成输出序列中的每个标记,这要求在每一步重复计算注意力分数,导致推理时间变慢。如表1所示,与RNNs和Transformers不同,它们仅限于支持一种类型的计算,离散SSMs具有支持递归和卷积计算的灵活性,这得益于它们的线性属性。这种独特的能力允许SSMs不仅实现有效的推理,还实现并行训练。然而,应该注意的是,大多数传统的SSM是时间不变的,这意味着它们的A、B、C和Δ与模型输入x无关。这将限制上下文感知建模,导致SSMs在某些任务中的性能下降,如选择性复制。
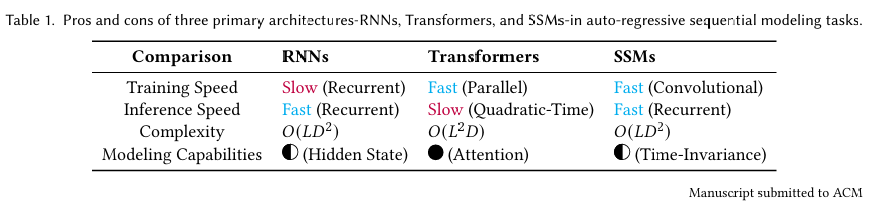
表1. 在自回归序列建模任务中,三种主要架构-RNNs、Transformers和SSMs-的优缺点比较。
若没有本文 Issue,您可以使用 Comment 模版新建。